从ECMAScript规范解读this
这一小节比较晦涩难懂,目前简单的了解一下就行,有需要再深入研究
转载于 https://github.com/mqyqingfeng/Blog/issues/7
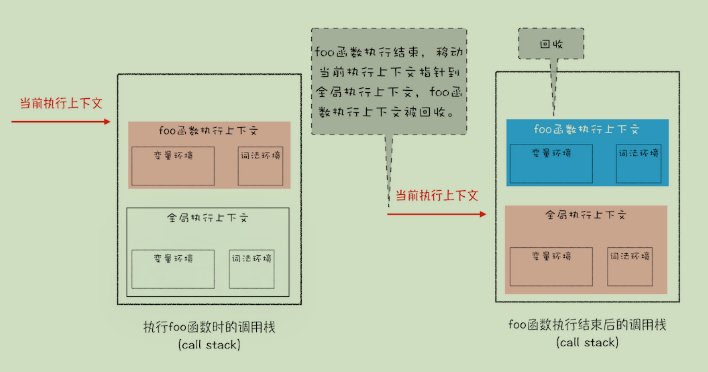
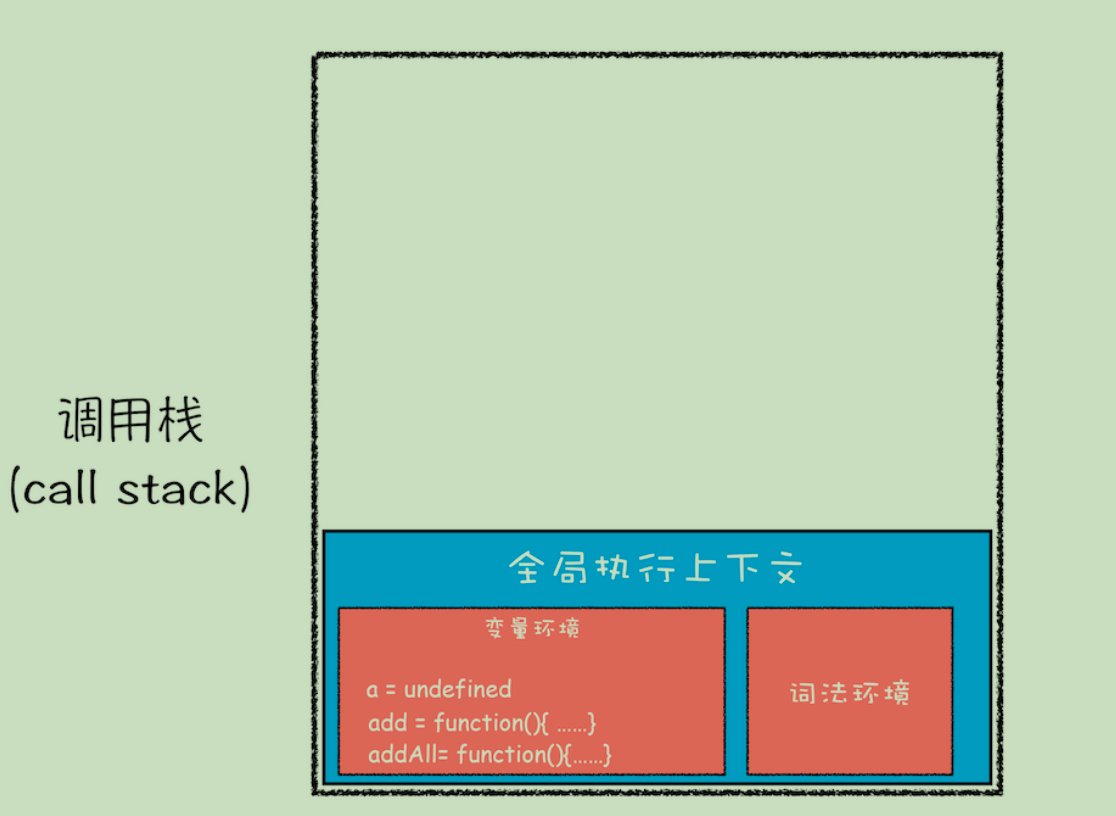
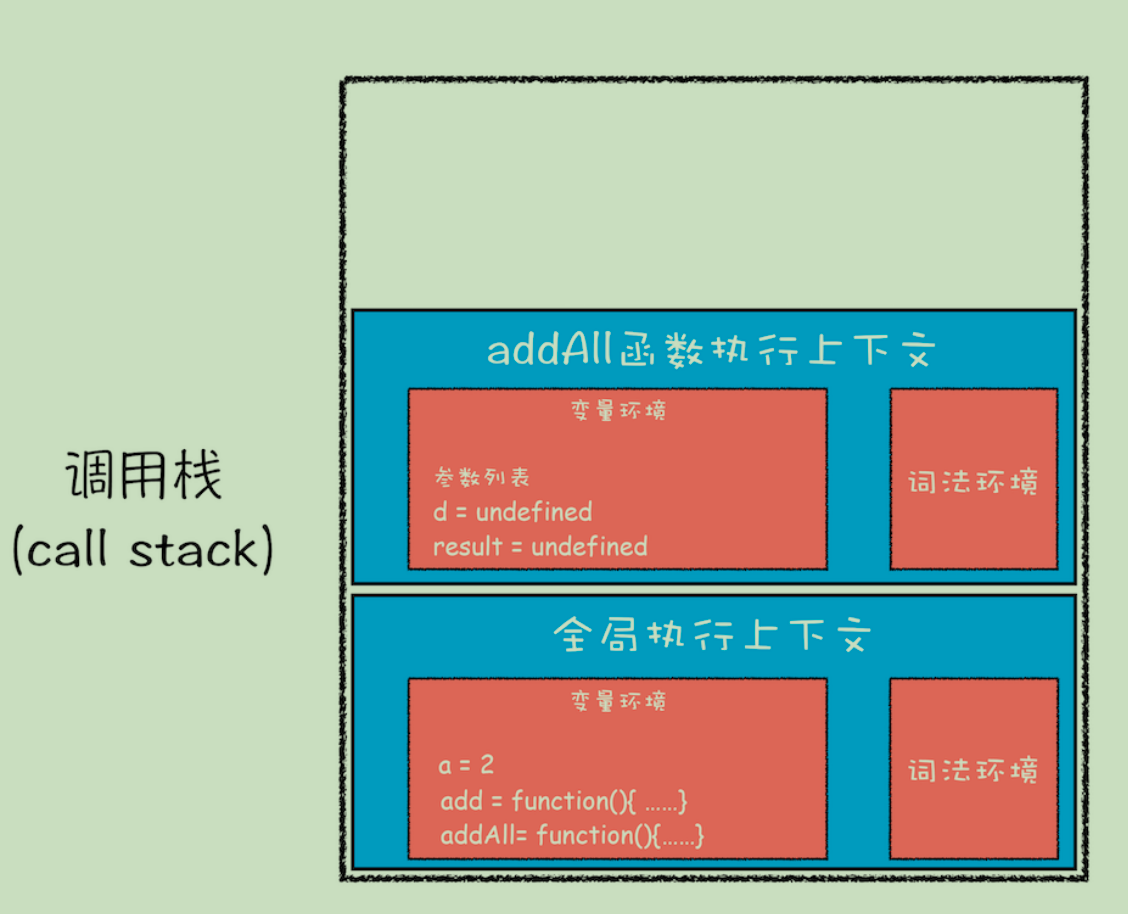
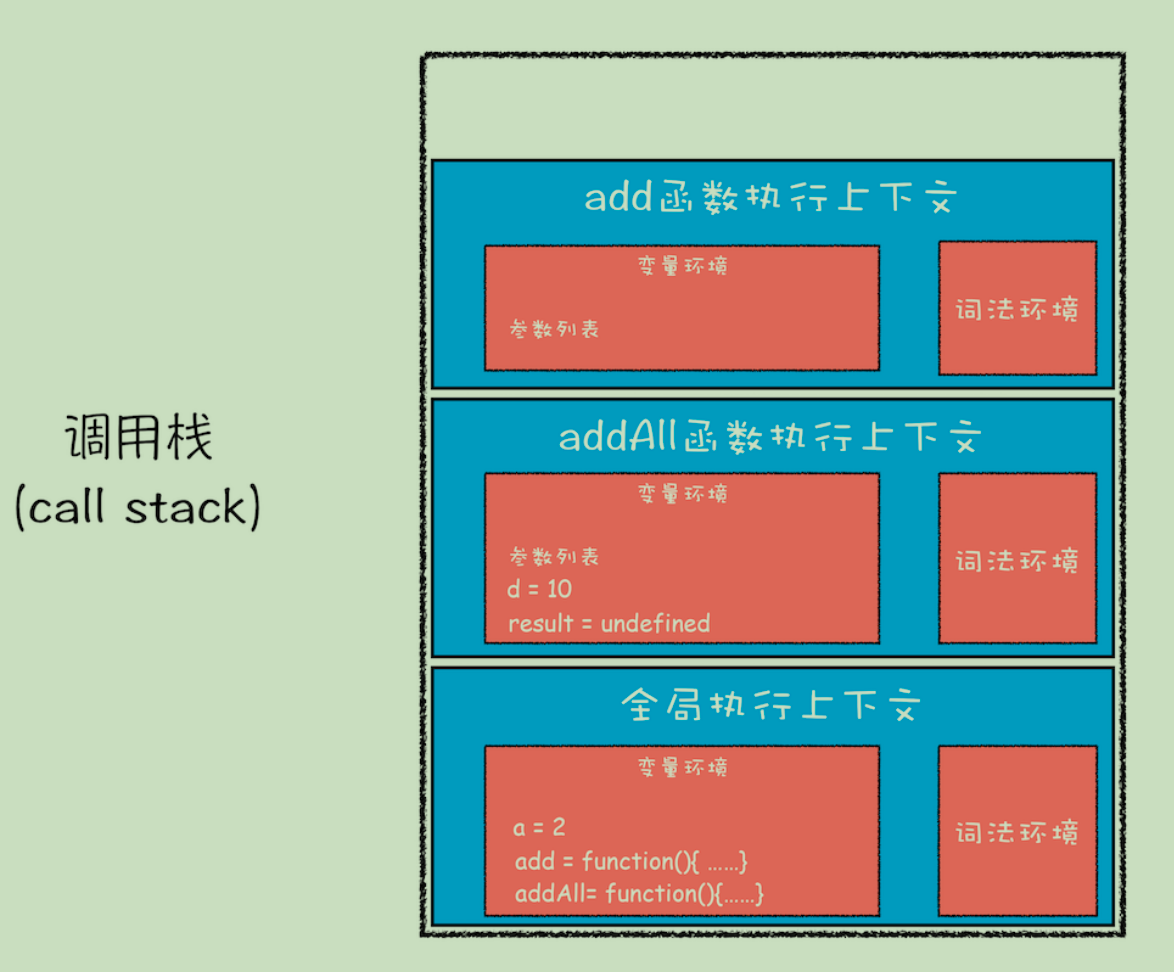
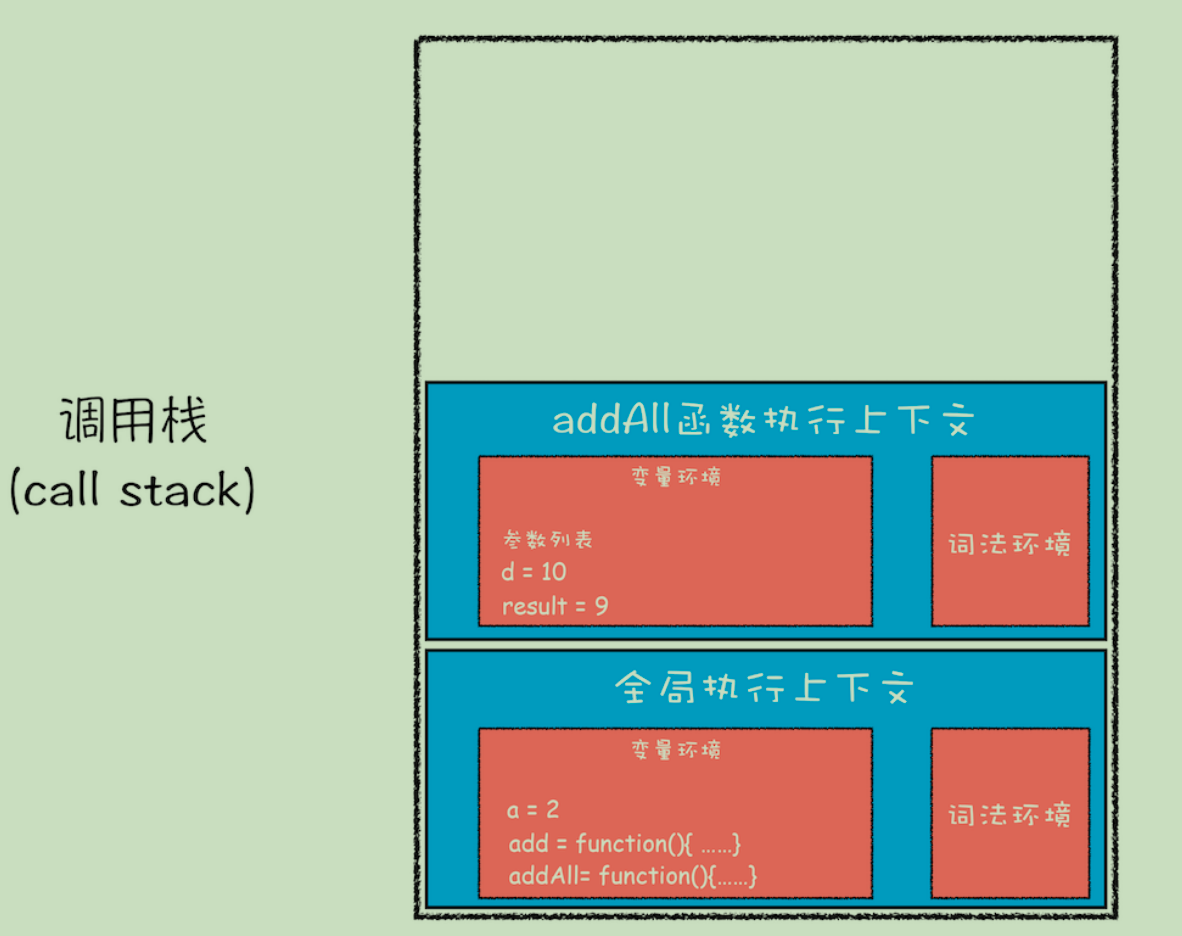
当JavaScript代码执行一段可执行代码(executable code)时,会创建对应的执行上下文(execution context)。
对于每个执行上下文,都有三个重要属性
- 变量对象(Variable object,VO)
- 作用域链(Scope chain)
- this
今天重点讲讲 this,然而不好讲。
……
因为我们要从 ECMAScript5 规范开始讲起。
先奉上 ECMAScript 5.1 规范地址:
英文版:http://es5.github.io/#x15.1
中文版:http://yanhaijing.com/es5/#115
让我们开始了解规范吧!
Types
首先是第 8 章 Types:
Types are further subclassified into ECMAScript language types and specification types.
An ECMAScript language type corresponds to values that are directly manipulated by an ECMAScript programmer using the ECMAScript language. The ECMAScript language types are Undefined, Null, Boolean, String, Number, and Object.
A specification type corresponds to meta-values that are used within algorithms to describe the semantics of ECMAScript language constructs and ECMAScript language types. The specification types are Reference, List, Completion, Property Descriptor, Property Identifier, Lexical Environment, and Environment Record.
我们简单的翻译一下:
ECMAScript 的类型分为语言类型和规范类型。
ECMAScript 语言类型是开发者直接使用 ECMAScript 可以操作的。其实就是我们常说的Undefined, Null, Boolean, String, Number, 和 Object。
而规范类型相当于 meta-values,是用来用算法描述 ECMAScript 语言结构和 ECMAScript 语言类型的。规范类型包括:Reference, List, Completion, Property Descriptor, Property Identifier, Lexical Environment, 和 Environment Record。
没懂?没关系,我们只要知道在 ECMAScript 规范中还有一种只存在于规范中的类型,它们的作用是用来描述语言底层行为逻辑。
今天我们要讲的重点是便是其中的 Reference 类型。它与 this 的指向有着密切的关联。
Reference
那什么又是 Reference ?
让我们看 8.7 章 The Reference Specification Type:
The Reference type is used to explain the behaviour of such operators as delete, typeof, and the assignment operators.
所以 Reference 类型就是用来解释诸如 delete、typeof 以及赋值等操作行为的。
抄袭尤雨溪大大的话,就是:
这里的 Reference 是一个 Specification Type,也就是 “只存在于规范里的抽象类型”。它们是为了更好地描述语言的底层行为逻辑才存在的,但并不存在于实际的 js 代码中。
再看接下来的这段具体介绍 Reference 的内容:
A Reference is a resolved name binding.
A Reference consists of three components, the base value, the referenced name and the Boolean valued strict reference flag.
The base value is either undefined, an Object, a Boolean, a String, a Number, or an environment record (10.2.1).
A base value of undefined indicates that the reference could not be resolved to a binding. The referenced name is a String.
==这段讲述了 Reference 的构成,由三个组成部分,分别是==:
- base value
- referenced name
- strict reference
可是这些到底是什么呢?
我们简单的理解的话:
base value 就是属性所在的对象或者就是 EnvironmentRecord,它的值只可能是 undefined, an Object, a Boolean, a String, a Number, or an environment record 其中的一种。
referenced name 就是属性的名称。
举个例子:
1 | var foo = 1; |
再举个例子:
1 | var foo = { |
而且规范中还提供了获取 Reference 组成部分的方法,比如 GetBase 和 IsPropertyReference。
这两个方法很简单,简单看一看:
1.GetBase
GetBase(V). Returns the base value component of the reference V.
返回 reference 的 base value。
2.IsPropertyReference
IsPropertyReference(V). Returns true if either the base value is an object or HasPrimitiveBase(V) is true; otherwise returns false.
简单的理解:如果 base value 是一个对象,就返回true。
3.GetValue
除此之外,紧接着在 8.7.1 章规范中就讲了一个用于从 Reference 类型获取对应值的方法: GetValue。
简单模拟 GetValue 的使用:
1 | var foo = 1; |
GetValue 返回对象属性真正的值,但是要注意:
调用 GetValue,返回的将是具体的值,而不再是一个 Reference
这个很重要,这个很重要,这个很重要。
如何确定this的值
关于 Reference 讲了那么多,为什么要讲 Reference 呢?到底 Reference 跟本文的主题 this 有哪些关联呢?如果你能耐心看完之前的内容,以下开始进入高能阶段:
看规范 11.2.3 Function Calls:
这里讲了当函数调用的时候,如何确定 this 的取值。
只看第一步、第六步、第七步:
1.Let ref be the result of evaluating MemberExpression.
6.If Type(ref) is Reference, then
7.Else, Type(ref) is not Reference.
==让我们描述一下:==
1.计算 MemberExpression 的结果赋值给 ref
2.判断 ref 是不是一个 Reference 类型
1 | 2.1 如果 ref 是 Reference,并且 IsPropertyReference(ref) 是 true, 那么 this 的值为 GetBase(ref) |
具体分析
让我们一步一步看:
- 计算 MemberExpression 的结果赋值给 ref
什么是 MemberExpression?看规范 11.2 Left-Hand-Side Expressions:
MemberExpression :
- PrimaryExpression // 原始表达式 可以参见《JavaScript权威指南第四章》
- FunctionExpression // 函数定义表达式
- MemberExpression [ Expression ] // 属性访问表达式
- MemberExpression . IdentifierName // 属性访问表达式
- new MemberExpression Arguments // 对象创建表达式
举个例子:
1 | function foo() { |
所以简单理解 MemberExpression 其实就是()左边的部分。
2.判断 ref 是不是一个 Reference 类型。
关键就在于看规范是如何处理各种 MemberExpression,返回的结果是不是一个Reference类型。
举最后一个例子:
1 | var value = 1; |
foo.bar()
在示例 1 中,MemberExpression 计算的结果是 foo.bar,那么 foo.bar 是不是一个 Reference 呢?
查看规范 11.2.1 Property Accessors,这里展示了一个计算的过程,什么都不管了,就看最后一步:
Return a value of type Reference whose base value is baseValue and whose referenced name is propertyNameString, and whose strict mode flag is strict.
我们得知该表达式返回了一个 Reference 类型!
根据之前的内容,我们知道该值为:
1 | var Reference = { |
接下来按照 2.1 的判断流程走:
2.1 如果 ref 是 Reference,并且 IsPropertyReference(ref) 是 true, 那么 this 的值为 GetBase(ref)
该值是 Reference 类型,那么 IsPropertyReference(ref) 的结果是多少呢?
前面我们已经铺垫了 IsPropertyReference 方法,如果 base value 是一个对象,结果返回 true。
base value 为 foo,是一个对象,所以 IsPropertyReference(ref) 结果为 true。
这个时候我们就可以确定 this 的值了:
1 | this = GetBase(ref), |
GetBase 也已经铺垫了,获得 base value 值,这个例子中就是foo,所以 this 的值就是 foo ,示例1的结果就是 2!
唉呀妈呀,为了证明 this 指向foo,真是累死我了!但是知道了原理,剩下的就更快了。
(foo.bar)()
看示例2:
1 | console.log((foo.bar)()); |
foo.bar 被 () 包住,查看规范 11.1.6 The Grouping Operator
直接看结果部分:
Return the result of evaluating Expression. This may be of type Reference.
NOTE This algorithm does not apply GetValue to the result of evaluating Expression.
实际上 () 并没有对 MemberExpression 进行计算,所以其实跟示例 1 的结果是一样的。
(foo.bar = foo.bar)()
看示例3,有赋值操作符,查看规范 11.13.1 Simple Assignment ( = ):
计算的第三步:
3.Let rval be GetValue(rref).
因为使用了 GetValue,所以返回的值不是 Reference 类型,
按照之前讲的判断逻辑:
2.3 如果 ref 不是Reference,那么 this 的值为 undefined
this 为 undefined,非严格模式下,this 的值为 undefined 的时候,其值会被隐式转换为全局对象。
(false || foo.bar)()
看示例4,逻辑与算法,查看规范 11.11 Binary Logical Operators:
计算第二步:
2.Let lval be GetValue(lref).
因为使用了 GetValue,所以返回的不是 Reference 类型,this 为 undefined
(foo.bar, foo.bar)()
看示例5,逗号操作符,查看规范11.14 Comma Operator ( , )
计算第二步:
2.Call GetValue(lref).
因为使用了 GetValue,所以返回的不是 Reference 类型,this 为 undefined
揭晓结果
所以最后一个例子的结果是:
1 | var value = 1; |
注意:以上是在非严格模式下的结果,严格模式下因为 this 返回 undefined,所以示例 3 会报错。
补充
最最后,忘记了一个最最普通的情况:
1 | function foo() { |
MemberExpression 是 foo,解析标识符,查看规范 10.3.1 Identifier Resolution,会返回一个 Reference 类型的值:
1 | var fooReference = { |
接下来进行判断:
2.1 如果 ref 是 Reference,并且 IsPropertyReference(ref) 是 true, 那么 this 的值为 GetBase(ref)
因为 base value 是 EnvironmentRecord,并不是一个 Object 类型,还记得前面讲过的 base value 的取值可能吗? 只可能是 undefined, an Object, a Boolean, a String, a Number, 和 an environment record 中的一种。
IsPropertyReference(ref) 的结果为 false,进入下个判断:
2.2 如果 ref 是 Reference,并且 base value 值是 Environment Record, 那么this的值为 ImplicitThisValue(ref)
base value 正是 Environment Record,所以会调用 ImplicitThisValue(ref)
查看规范 10.2.1.1.6,ImplicitThisValue 方法的介绍:该函数始终返回 undefined。
所以最后 this 的值就是 undefined。
多说一句
尽管我们可以简单的理解 this 为调用函数的对象,如果是这样的话,如何解释下面这个例子呢?
1 | var value = 1; |
此外,又如何确定调用函数的对象是谁呢?在写文章之初,我就面临着这些问题,最后还是放弃从多个情形下给大家讲解 this 指向的思路,而是追根溯源的从 ECMASciript 规范讲解 this 的指向,尽管从这个角度写起来和读起来都比较吃力,但是一旦多读几遍,明白原理,绝对会给你一个全新的视角看待 this 。而你也就能明白,尽管 foo() 和 (foo.bar = foo.bar)() 最后结果都指向了 undefined,但是两者从规范的角度上却有着本质的区别。
此篇讲解执行上下文的 this,即便不是很理解此篇的内容,依然不影响大家了解执行上下文这个主题下其他的内容。所以,依然可以安心的看下一篇文章。