var lengthOfLongestSubstring = function(s) { // 处理 s=” “ 返回 1 if(s&&!s.trim()){ return 1 } let max = 0; let left = right = 0; const sw = new SliderWindow() while (right < s.length) { let flag = true sw.push(s[right++]) while (!sw.isAccord()) { if (flag) { flag = false if (right - 1 - left > max) { max = right - 1 - left } } sw.shift(s[left++]) flag = true } // 处理不会出现不符合情况的字符串 即 s=”a“ s="abc" if (right - left > max) { max = right - left } } return max }; class SliderWindow{ constructor() { this.window = {} this.count = 0 } push(s){ this.window[s] ? this.window[s]++ : this.window[s] = 1 if (this.window[s] === 2) { this.count++ } } shift(s){ this.window[s]-- // 同上 if (this.window[s] === 1) { this.count-- } } isAccord(){ return !this.count } }
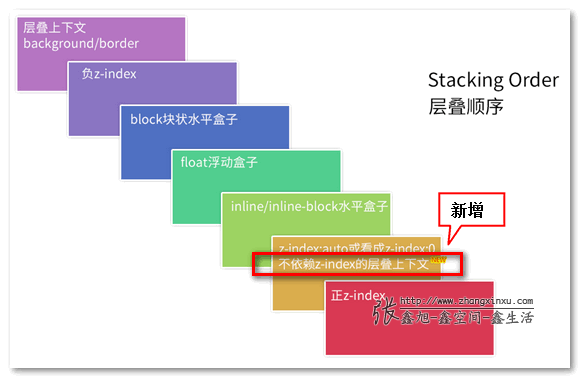
总结
代码主体部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14
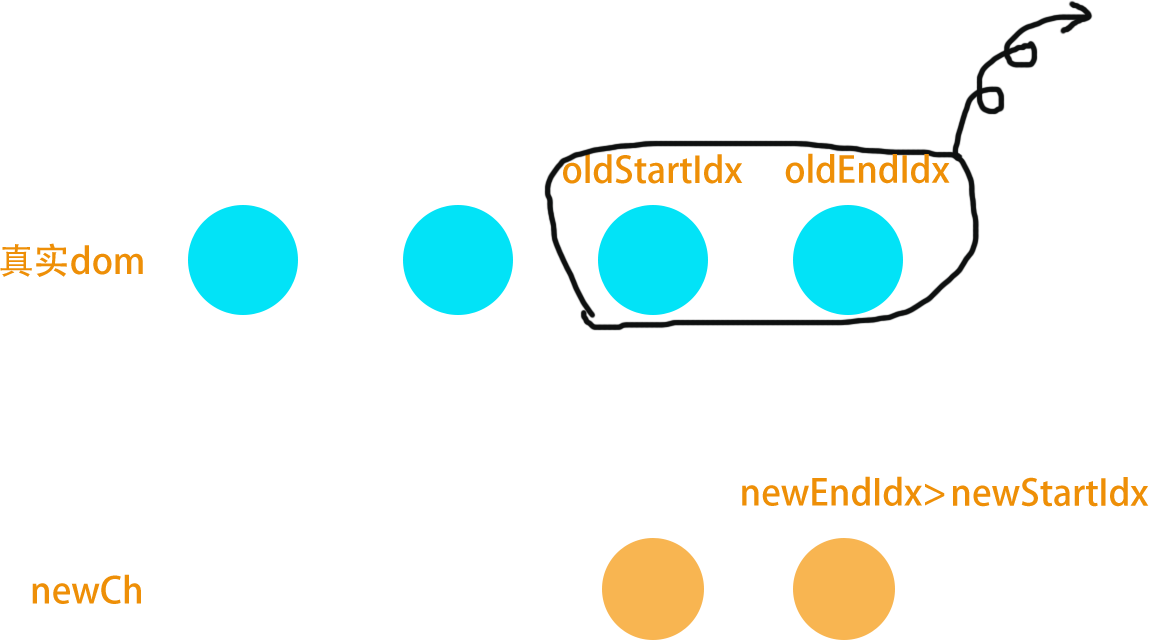
let left = right = 0 while (right < s.length) { // 队尾加数据 sw.push(s[right]) right++ while (sw need shink) { // 对头删除数据 sw.shift(s[left]) left++ // 依据题目在合适的位置进行更新 } // 依据题目在合适的位置进行更新 }
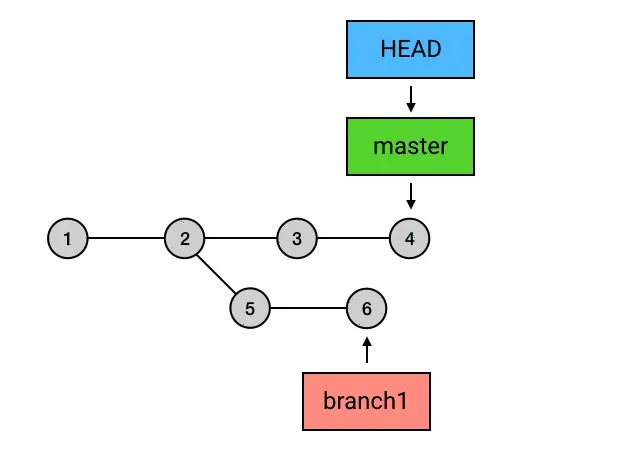
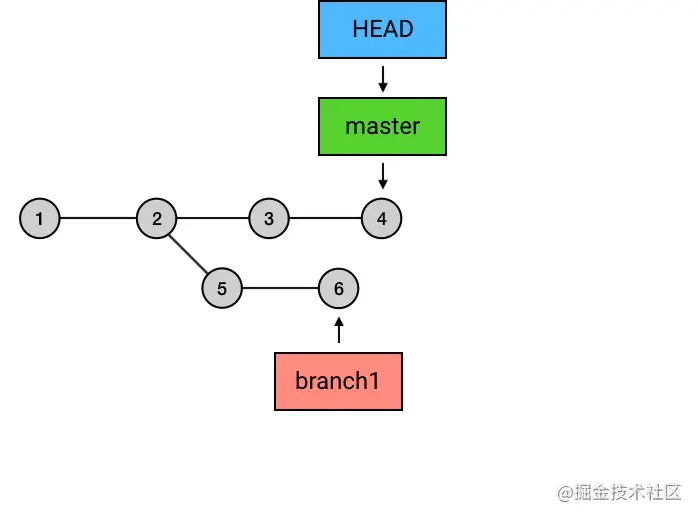
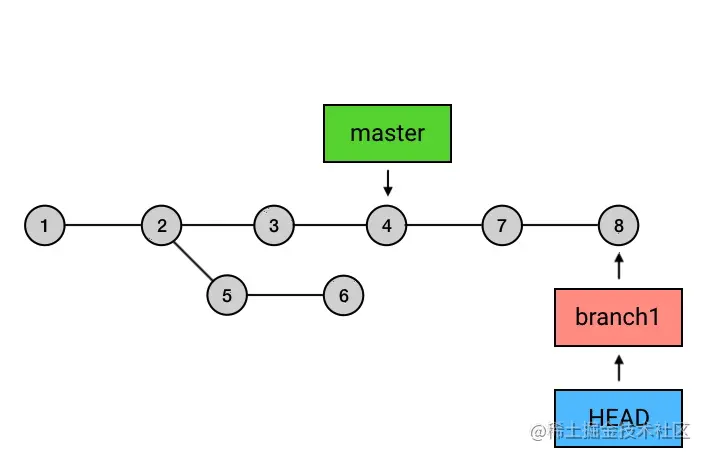
git stash pop :命令恢复之前缓存的工作目录,将缓存堆栈中的对应stash删除,并将对应修改应用到当前的工作目录下,默认为第一个stash,即stash@{0},如果要应用并删除其他stash,命令:git stash pop stash@{$num} ,比如应用并删除第二个:git stash pop stash@{1}
git stash drop stash@{$num}:丢弃stash@{$num}存储,从列表中删除这个存储192.168.1.110
git stash clear:删除所有缓存的stash
查看改动
查看改动内容的方法,大致有这么几类:
查看历史中的多个commit:log
查看详细改动: git log -p
查看大致改动:git log --stat
查看具体某个commit:show
要看最新 commit ,直接输入 git show ;要看指定 commit ,输入 git show commit的引用或SHA-1
function handle(num){ switch (num){ case 1: console.log(1) case 2: console.log(2) case 3: console.log(3) case 4: console.log(4) case 5: console.log(5) case 6: console.log(6) default: break; } } handle(3) // 3 4 5 6
console.log(c); function c(a) { console.log(a); var a = 3; } //function c(){...} //案例2 console.log(c); var c = function (a) { console.log(a); var a = 3; } //undefined
重复声明会被忽略
1 2 3 4
foo(); // 1 var foo; function foo() { console.log( 1 ); } foo = function() { console.log( 2 ); };
注意,var foo 尽管出现在 function foo()… 的声明之前,但它是重复的声明(因此被忽略了),因为函数声明会被提升到普通变量之前。
看一下你所不知道的JavaScript上 40页
19 npx讲解
npx 会帮你执行依赖包里的二进制文件 举个例子:
1 2 3
npm i webpack -D //非全局安装 //如果要执行 webpack 的命令 ./node_modules/.bin/webpack -v
constADDRESS = 'One Infinite Loop, Cupertino 95014'; var cityStateRegex = /^(.+)[,\\s]+(.+?)\s*(\d{5})?$/; var match = ADDRESS.match(cityStateRegex) var city = match[1]; var state = match[2]; saveCityState(city, state);
functionshowList(employees) { employees.forEach(employee => { var expectedSalary = employee.calculateExpectedSalary(); var experience = employee.getExperience(); var portfolio;
程序在某些情况下确实需要副作用这一行为,如先前例子中的写文件。这时应该将这些功能集中在一起,不要用多个函数/类修改某个文件。用且只用一个 service 完成这一需求。
反例:
1 2 3 4 5 6 7 8 9 10 11
// Global variable referenced by following function. // If we had another function that used this name, now it'd be an array and it could break it. var name = 'Ryan McDermott';
functionsplitIntoFirstAndLastName() { name = name.split(' '); }
// It doesn't have to be prefixed with `get` or `set` to be a getter/setter withdraw(amount) { if (verifyAmountCanBeDeducted(amount)) { this.balance -= amount; } } }
classAjaxRequester { constructor() { // What if we wanted another HTTP Method, like DELETE? We would have to // open this file up and modify this and put it in manually. this.HTTP_METHODS = ['POST', 'PUT', 'GET']; }
functionrenderLargeRectangles(rectangles) { rectangles.forEach((rectangle) => { rectangle.setWidth(4); rectangle.setHeight(5); let area = rectangle.getArea(); // BAD: Will return 25 for Square. Should be 20. rectangle.render(area); }) }
let rectangles = [newRectangle(), newRectangle(), newSquare()]; renderLargeRectangles(rectangles);
let $ = newDOMTraverser({ rootNode: document.getElementsByTagName('body'), animationModule: function() {} // Most of the time, we won't need to animate when traversing. // ... });
// BAD: We have created a dependency on a specific request implementation. // We should just have requestItems depend on a request method: `request` this.requester = newInventoryRequester(); }
// By constructing our dependencies externally and injecting them, we can easily // substitute our request module for a fancy new one that uses WebSockets. let inventoryTracker = newInventoryTracker(['apples', 'bananas'], newInventoryRequesterV2()); inventoryTracker.requestItems();
// Bad because Employees "have" tax data. EmployeeTaxData is not a type of Employee classEmployeeTaxDataextendsEmployee { constructor(ssn, salary) { super(); this.ssn = ssn; this.salary = salary; }
try { functionThatMightThrow(); } catch (error) { // One option (more noisy than console.log): console.error(error); // Another option: notifyUserOfError(error); // Another option: reportErrorToService(error); // OR do all three! }
getdata() .then(data => { functionThatMightThrow(data); }) .catch(error => { // One option (more noisy than console.log): console.error(error); // Another option: notifyUserOfError(error); // Another option: reportErrorToService(error); // OR do all three! });
// Loop through every character in data for (var i = 0; i < length; i++) { // Get character code. var char = data.charCodeAt(i); // Make the hash hash = ((hash << 5) - hash) + char; // Convert to 32-bit integer hash = hash & hash; } }
正例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
functionhashIt(data) { var hash = 0; var length = data.length;
for (var i = 0; i < length; i++) { var char = data.charCodeAt(i); hash = ((hash << 5) - hash) + char;
/* The MIT License (MIT) Copyright (c) 2016 Ryan McDermott Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE */
,Unicode提供了4种规范化形式,可以将类似上面的字符规范化为一致的格式,无论 底层字符的代码是什么。这 4种规范化形式是:NFD(Normalization Form D)、NFC(Normalization Form C)、 NFKD(Normalization Form KD)和 NFKC(Normalization Form KC)。可以使用 normalize()方法对字 符串应用上述规范化形式,使用时需要传入表示哪种形式的字符串:”NFD”、”NFC”、”NFKD”或”NFKC”。
let text = "cat, bat, sat, fat"; let result = text.replace("at", "ond"); console.log(result); // "cond, bat, sat, fat" result = text.replace(/at/g, "ond"); console.log(result); // "cond, bond, sond, fond"