箭头函数与call
在看阮一峰大佬的ES6时,看到一个关于箭头函数和this的例子
1 | function foo() { |
输出结果竟然是42,我一直以为箭头函数的this从函数定义时就已经固定不变了,es6的教程也看过几遍,还是看书不仔细漏过了这个问题
在疑惑后也思考研究了一下,结合搜索到的例子,得出一下结论:
首先不使用箭头函数
1 | function foo() { |
此时结果都是可以预期的,第一行输出42,是因为call函数改变了foo的指针执行,指向为{id: 42}
第二行输出21,是因为setTimeout是挂载在window下面的。setTimeout实际上又改变了this的指针指向,将this又指向了window。因此输出21。
将函数改为箭头函数
1 | function foo() { |
此时第一行依旧输出42,这一点是肯定的
分析第二行,箭头函数导致this总是指向函数(箭头函数)定义生效时所在的对象,这句话换个方式理解比较容易理解和记忆,即箭头函数的this指向和将箭头函数的内容拿到函数外层的this指向是一致的
结合上面的例子就是 第二行的this应该和第一行的this是一致的
看到闭包以后,我觉得箭头函数既然没有自己的this,是不是相当于普通函数获取上一级的变量一样。。。?
再看一下这个例子
1 | var myObj = { |
可以看到 call apply 和bind 也无法改变箭头函数的this,始终取决于上层上下文的this
蝉原则
“蝉原则”与CSS3随机多背景随机圆角等效果
什么是“蝉原则”?
“蝉原则”,英文称作“cicada principle”,是一种让事物的重复出现符合“自然随机性”的规则,为什么这么说呢?
“蝉原则”源自于北美,中国似乎并未有这样的说法,这背后是有有故事的:
北美和东亚蝉的种群是不一样的,在东亚蝉的幼虫生活在土中3年5年或7年;但是北美有一种周期蝉(Magicicada),其生命周期为十三年或十七年,也被称为十七年蝉或十三年蝉。东亚的蝉生命周期短,因此,给人感觉好像每年都有很多蝉,而北美的周期蝉的生命周期很长,因此能够让人明显感觉到每隔十几年蝉的数量就会大规模爆发一下,于是就会引发一些科学家的好奇,为什么生命周期是十三年或者十七年呢?
蝉的天敌鸟类其繁荣萧条周期是具有规律性的(一般2至6年),然后不断重复。十三年或者十七年中的13和17都是质数,而吃蝉的鸟类一般寿命都不超过13年,因此就不会遇到上一世代所遇到的天敌。
东亚蝉的幼虫生活的年限比较短,可能与东亚的主要鸟类种群寿命不长有关,例如麻雀就2年寿命。还有一个很重要的原因,就是一片区域的蝉他不止一个种群,而使用质数作为生命周期年数就可以避免钻出泥土时可以和别种群的蝉类一起钻出,这样竞争压力就会小。例如,北美的十七年蝉和十三年蝉每221年才会出现同时爆发的情况。
这种以质数作为循环周期来增加“自然随机性”的策略就称之为“蝉原则”。
那“蝉原则”对我们网页设计有什么启示呢?那就是可以以最小成本实现更自然的随机效果。
本文就演示两个借助“蝉原则”和CSS3特性实现随机效果的例子。
“蝉原则”下的CSS3 multiple Backgrounds随机多背景
在著名的CSS3背景底纹站点有这么一个案例,如下截图:

从名称就可以看出其背后的原理,Cicada stripes是“蝉条纹”的意思,意思是说这里的随机背景线条实际上是使用“蝉原则”实现的。代码如下:
1 | .stripes { |
上面CSS代码显示总共有4个渐变背景图,然后每个背景图的颜色透明度以及区域范围都不一样,然后最终的随机效果,最关键的就是控制4个背景图循环尺寸的background-size属性,其对应的4个尺寸值13px, 29px, 37px, 53px全部都是质数,于是保证了最大的自然随机,最终的随机线条效果更自然。
“蝉原则”下的CSS3 border-radius随机圆角效果
这里随机圆角效果可以参见这个站点:http://2016.uxlondon.com/speakers,效果截图如下:

可以看到嘉宾的头像的圆角的大小都是随机的,不规则的,有的这里扁,又是那里歪,其实现也利用的“蝉原则”。
其实现的原理是对:nth-child进行自然随机,按照原作者的话说,其原本是想类似下面实现:
1 | list:nth-child(2n) {} |
但是发现不能覆盖所有的列表项,反而有些不自然,因此,进行了如下的改进:
1 | list:nth-child(2n + 1) {} |
也就是后面再加一个小一号的质数值,于是,再配合默认效果,天衣无缝的随机列表交互就实现了,拿2n+1项举例:
1 | list { |
于是效果达成!
质数表
1 | 2 3 5 7 11 13 17 |
防抖和节流
在前端开发的过程中,我们经常会需要绑定一些持续触发的事件,如 resize、scroll、mousemove 等等,但有些时候我们并不希望在事件持续触发的过程中那么频繁地去执行函数。
通常这种情况下我们怎么去解决的呢?一般来讲,防抖和节流是比较好的解决方案。
用一句比较剪短的话形容两者的区别:
防抖是控制次数,节流是控制频率
防抖
- 非立即执行版:
触发事件后函数不会立即执行,而是在 n 秒后执行,如果在 n 秒内又触发了事件,则会重新计算函数执行时间
1 | function debounce(func, wait) { |
- 立即执行版:
立即执行版的意思是触发事件后函数会立即执行,然后 n 秒内不触发事件才能继续执行函数的效果。
1 | function debounce(func,wait) { |
节流
1 | function throttle(func, wait) { |
leetCode
卡牌分组
给定一副牌,每张牌上都写着一个整数。
此时,你需要选定一个数字 X,使我们可以将整副牌按下述规则分成 1 组或更多组:
每组都有 X 张牌。组内所有的牌上都写着相同的整数。
仅当你可选的 X >= 2 时返回 true。
示例 1:
输入:[1,2,3,4,4,3,2,1]
输出:true
解释:可行的分组是 [1,1],[2,2],[3,3],[4,4]
示例 2:
输入:[1,1,1,2,2,2,3,3]
输出:false
解释:没有满足要求的分组。
示例 3:
输入:[1]
输出:false
解释:没有满足要求的分组。
示例 4:
输入:[1,1]
输出:true
解释:可行的分组是 [1,1]
示例 5:
输入:[1,1,2,2,2,2]
输出:true
解释:可行的分组是 [1,1],[2,2],[2,2]
涉及点
- 辗转相除法 求最大公约数
- 利用哈希表计算元素出现次数
自己的解答
- 首先利用
ES6新数据结构Map,计算元素出现的次数 - 使用
...运算符将其转为数组,不要忘记利用 (Map.protype.values()返回的是一个新的Iterator对象) - 然后遍历数组,取当前项与后一项做辗转相除法,求出最大公约数后赋值给后一项,直到运算完成
- 这里需要考虑[1,1]的这种情况,由于次数数组程度为 1 ,所以做了特殊处理
- 然后只要判断最后的最大公约数是否大于 2 即可
1 | var hasGroupsSizeX = function(deck) { |
网上的解答,在此仅展示部分代码,代码取第一位做了一次重复运算,所有不需要考虑特殊情况
1 | /* |
605 种花问题
假设你有一个很长的花坛,一部分地块种植了花,另一部分却没有。可是,花卉不能种植在相邻的地块上,它们会争夺水源,两者都会死去。
给定一个花坛(表示为一个数组包含0和1,其中0表示没种植花,1表示种植了花),和一个数 n 。能否在不打破种植规则的情况下种入 n 朵花?能则返回True,不能则返回False。
示例 1:
输入: flowerbed = [1,0,0,0,1], n = 1
输出: True
示例 2:
输入: flowerbed = [1,0,0,0,1], n = 2
输出: False
注意:
- 数组内已种好的花不会违反种植规则。
- 输入的数组长度范围为 [1, 20000]。
- n 是非负整数,且不会超过输入数组的大小。
官方解答, 有几个缺点
- 边界条件过于负责
- 遍历次数较多
1 | var canPlaceFlowers = function(flowerbed, n) { |
较好的解答, 通俗易懂
- 两边不为1,隐含着最左和最右的边界条件
- 当符合种花条件时,将遍历序号 +1 取代赋值,减少了遍历次数
1 | var canPlaceFlowers = function (flowerbed, n) { |
格雷编码
优秀解题思路-附带图解
主要就是找规律,据说数字电路课有讲解
我的解答
1 |
84 柱状图中最大的矩形
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。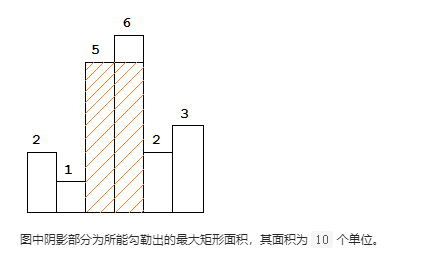
我的解法,用最原始的方法进行解答,理论上可行,但是空间复杂度和时间复杂度太复杂了
1 | var largestRectangleArea = function(heights) { |
1 | const largestRectangleArea = (heights) => { |
面试中遇到的算法题 两个有序数组合并为一个有序数组
两个数组let arr1 = [0, 3, 5, 8, 15, 19]let arr2 = [1, 2, 7, 13, 16, 17, 18]
结果输出为[0, 1, 2, 3, 5, 7, 8, 13, 15, 16, 17, 18]
假设两个数组都为升序排列
1 | let arr1 = [-1, 0, 1, 5, 8, 15, 19, 22, 33] |
let arr1 = [-1, 0, 1, 5, 8, 15, 19, 22, 33]
let arr2 = [3, 4, 7, 13, 15, 16, 17, 18, 19, 20, 33, 34, 35]
function handle(arr1, arr2) {
if(arr1.length === 0){
return
}else{
var v1 = arr1.shift()
addPosition(v1, arr2, 0)
return handle(arr1, arr2)
}
}
function addPosition(v1, arr2, index){
if(index >= arr2.length){
return
}else{
if(v1 <= arr2[index] && (index === 0 || v1 > arr2[index - 1])){
arr2.splice(index, 0, v1)
return
} else if(index === arr2.length - 1) {
if(v1 > arr2[index]){
arr2.splice(index + 1, 0, v1)
return
}
}
return addPosition(v1, arr2, index + 1)
}
}
handle(arr1, arr2)
console.log(arr2);
1 |
|
let arr1 = [-1, 0, 1, 5, 8, 15, 19, 22, 33]
let arr2 = [3, 4, 7, 13, 15, 16, 17, 18, 19, 20, 33, 34, 35]
function handle(arr1, arr2) {
if(arr1.length === 0){
return
}else{
var v1 = arr1.shift()
addPosition(v1, arr2, 0)
return handle(arr1, arr2)
}
}
function addPosition(v1, arr2, index){
if(index >= arr2.length){
return
}else{
// 优化了下列代码
if(v1 <= arr2[index]){
arr2.splice(index, 0, v1)
return
} else if(index === arr2.length - 1) {
arr2.splice(index + 1, 0, v1)
return
}
// 优化结束
return addPosition(v1, arr2, index + 1)
}
}
handle(arr1, arr2)
console.log(arr2);
正则疑难点记录
正则疑难点记录
贪婪、非贪婪与独占模式
1 | // 贪婪匹配 |
在字符后加上一个问号(?)则可以开启懒惰模式,在该模式下,正则引擎尽可能少的重复匹配字符,匹配成功之后它会继续匹配剩余的字符串
1 | // 非贪婪匹配 则可以开启懒惰模式,在该模式下,正则引擎尽可能少的重复匹配字符,匹配成功之后它会继续匹配剩余的字符串 |
在表达式后加上一个加号(+),则会开启独占模式。同贪婪模式一样,独占模式一样会匹配最长。不过在独占模式下,正则表达式尽可能长地去匹配字符串,一旦匹配不成功就会结束匹配而不会回溯。
1 | "c.*+t" => The fat cat sat on the mat. |
0次匹配 * ?
- 匹配>=0个重复的在号之前的字符。
- 匹配>=1个重复的+号前的字符。
- ? 标记?之前的字符为可选(代表0次或者1次).
看一下下列代码,匹配模式是/[a-z]*/
1 | var str = "The fata catqq sat on the mat."; |
结果如下,替换为/[a-z]?/结果也是一样的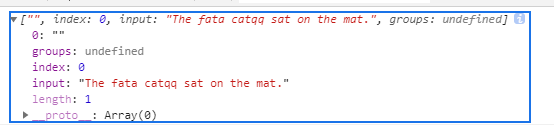
匹配到了一个""
现在添加一个全局搜索符 g
1 | var str = "The fata catqq sat on the mat."; |
结果如下图:
我非常疑惑为什么会匹配到 "" 下面是来自正则匹配的示意图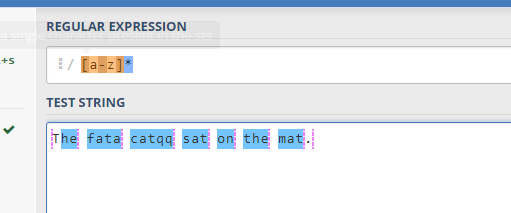
蓝色虚线表示""
如果把正则换成/[a-z]?/g结果如下所示
这是因为?开启了懒惰模式,正则引擎尽可能少的重复匹配字符,匹配成功之后它会继续匹配剩余的字符串
正则疑难点记录
什么是正则表达式?
正则表达式是一组由字母和符号组成的特殊文本,它可以用来从文本中找出满足你想要的格式的句子。
一个正则表达式是一种从左到右匹配主体字符串的模式。
“Regular expression”这个词比较拗口,我们常使用缩写的术语“regex”或“regexp”。
正则表达式可以从一个基础字符串中根据一定的匹配模式替换文本中的字符串、验证表单、提取字符串等等。
想象你正在写一个应用,然后你想设定一个用户命名的规则,让用户名包含字符、数字、下划线和连字符,以及限制字符的个数,好让名字看起来没那么丑。
我们使用以下正则表达式来验证一个用户名:
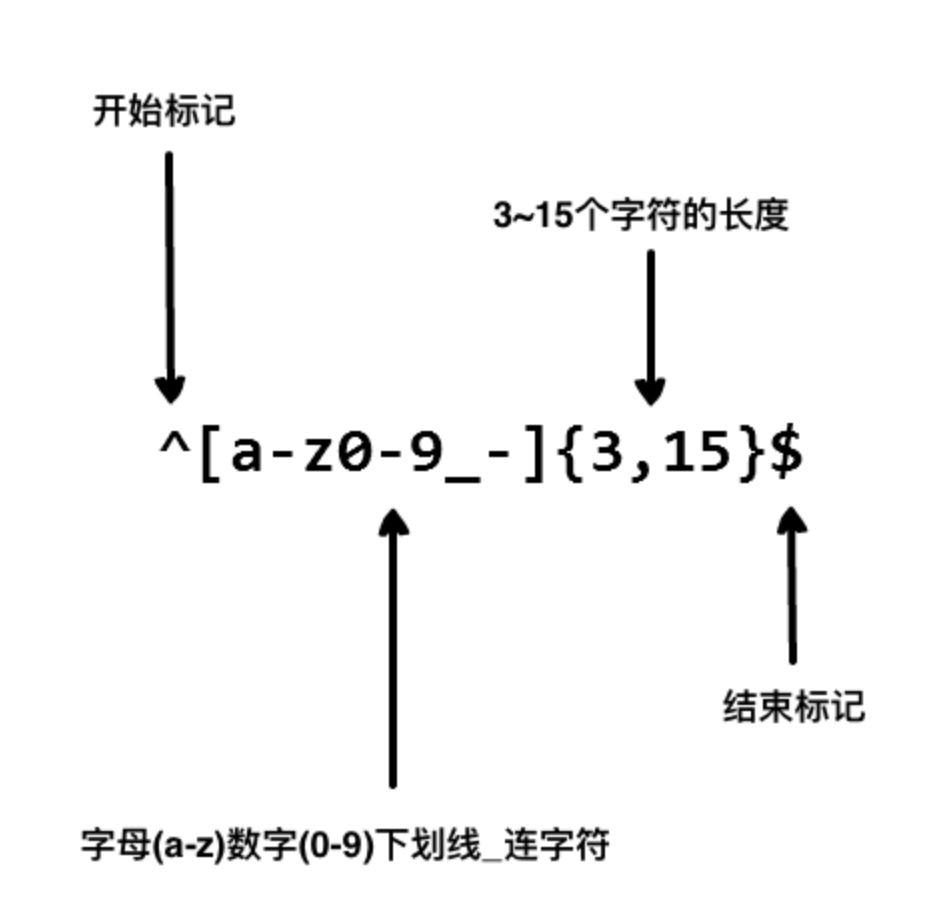
以上的正则表达式可以接受 john_doe、jo-hn_doe、john12_as。
但不匹配Jo,因为它包含了大写的字母而且太短了。
目录
- 目录
1. 基本匹配
正则表达式其实就是在执行搜索时的格式,它由一些字母和数字组合而成。
例如:一个正则表达式 the,它表示一个规则:由字母t开始,接着是h,再接着是e。
"the" => The fat cat sat on the mat.
正则表达式123匹配字符串123。它逐个字符的与输入的正则表达式做比较。
正则表达式是大小写敏感的,所以The不会匹配the。
"The" => The fat cat sat on the mat.
2. 元字符
正则表达式主要依赖于元字符。
元字符不代表他们本身的字面意思,他们都有特殊的含义。一些元字符写在方括号中的时候有一些特殊的意思。以下是一些元字符的介绍:
| 元字符 | 描述 |
|---|---|
| . | 句号匹配任意单个字符除了换行符。 |
| [ ] | 字符种类。匹配方括号内的任意字符。 |
| [^ ] | 否定的字符种类。匹配除了方括号里的任意字符 |
| * | 匹配>=0个重复的在*号之前的字符。 |
| + | 匹配>=1个重复的+号前的字符。 |
| ? | 标记?之前的字符为可选. |
| {n,m} | 匹配num个大括号之前的字符或字符集 (n <= num <= m). |
| (xyz) | 字符集,匹配与 xyz 完全相等的字符串. |
| | | 或运算符,匹配符号前或后的字符. |
| \ | 转义字符,用于匹配一些保留的字符 [ ] ( ) { } . * + ? ^ $ \ | |
| ^ | 从开始行开始匹配. |
| $ | 从末端开始匹配. |
2.1 点运算符 .
.是元字符中最简单的例子。.匹配任意单个字符,但不匹配换行符。
例如,表达式.ar匹配一个任意字符后面跟着是a和r的字符串。
".ar" => The car parked in the garage.
2.2 字符集
字符集也叫做字符类。
方括号用来指定一个字符集。
在方括号中使用连字符来指定字符集的范围。
在方括号中的字符集不关心顺序。
例如,表达式[Tt]he 匹配 the 和 The。
"[Tt]he" => The car parked in the garage.
方括号的句号就表示句号。
表达式 ar[.] 匹配 ar.字符串
"ar[.]" => A garage is a good place to park a car.
2.2.1 否定字符集
一般来说 ^ 表示一个字符串的开头,但它用在一个方括号的开头的时候,它表示这个字符集是否定的。
例如,表达式[^c]ar 匹配一个后面跟着ar的除了c的任意字符。
"[^c]ar" => The car parked in the garage.
2.3 重复次数
后面跟着元字符 +,* or ? 的,用来指定匹配子模式的次数。
这些元字符在不同的情况下有着不同的意思。
2.3.1 * 号
*号匹配 在*之前的字符出现大于等于0次。
例如,表达式 a* 匹配0或更多个以a开头的字符。表达式[a-z]* 匹配一个行中所有以小写字母开头的字符串。
"[a-z]*" => The car parked in the garage #21.
*字符和.字符搭配可以匹配所有的字符.*。*和表示匹配空格的符号\s连起来用,如表达式\s*cat\s*匹配0或更多个空格开头和0或更多个空格结尾的cat字符串。
"\s*cat\s*" => The fat cat sat on the concatenation.
2.3.2 + 号
+号匹配+号之前的字符出现 >=1 次。
例如表达式c.+t 匹配以首字母c开头以t结尾,中间跟着至少一个字符的字符串。
"c.+t" => The fat cat sat on the mat.
2.3.3 ? 号
在正则表达式中元字符 ? 标记在符号前面的字符为可选,即出现 0 或 1 次。
例如,表达式 [T]?he 匹配字符串 he 和 The。
"[T]he" => The car is parked in the garage.
"[T]?he" => The car is parked in the garage.
2.4 {} 号
在正则表达式中 {} 是一个量词,常用来限定一个或一组字符可以重复出现的次数。
例如, 表达式 [0-9]{2,3} 匹配最少 2 位最多 3 位 0~9 的数字。
"[0-9]{2,3}" => The number was 9.9997 but we rounded it off to 10.0.
我们可以省略第二个参数。
例如,[0-9]{2,} 匹配至少两位 0~9 的数字。
"[0-9]{2,}" => The number was 9.9997 but we rounded it off to 10.0.
如果逗号也省略掉则表示重复固定的次数。
例如,[0-9]{3} 匹配3位数字
"[0-9]{3}" => The number was 9.9997 but we rounded it off to 10.0.
2.5 (...) 特征标群
特征标群是一组写在 (...) 中的子模式。(...) 中包含的内容将会被看成一个整体,和数学中小括号( )的作用相同。例如, 表达式 (ab)* 匹配连续出现 0 或更多个 ab。如果没有使用 (...) ,那么表达式 ab* 将匹配连续出现 0 或更多个 b 。再比如之前说的 {} 是用来表示前面一个字符出现指定次数。但如果在 {} 前加上特征标群 (...) 则表示整个标群内的字符重复 N 次。
我们还可以在 () 中用或字符 | 表示或。例如,(c|g|p)ar 匹配 car 或 gar 或 par.
"(c|g|p)ar" => The car is parked in the garage.
2.6 | 或运算符
或运算符就表示或,用作判断条件。
例如 (T|t)he|car 匹配 (T|t)he 或 car。
"(T|t)he|car" => The car is parked in the garage.
2.7 转码特殊字符
反斜线 \ 在表达式中用于转码紧跟其后的字符。用于指定 { } [ ] / \ + * . $ ^ | ? 这些特殊字符。如果想要匹配这些特殊字符则要在其前面加上反斜线 \。
例如 . 是用来匹配除换行符外的所有字符的。如果想要匹配句子中的 . 则要写成 \. 以下这个例子 \.?是选择性匹配.
"(f|c|m)at\.?" => The fat cat sat on the mat.
2.8 锚点
在正则表达式中,想要匹配指定开头或结尾的字符串就要使用到锚点。^ 指定开头,$ 指定结尾。
2.8.1 ^ 号
^ 用来检查匹配的字符串是否在所匹配字符串的开头。
例如,在 abc 中使用表达式 ^a 会得到结果 a。但如果使用 ^b 将匹配不到任何结果。因为在字符串 abc 中并不是以 b 开头。
例如,^(T|t)he 匹配以 The 或 the 开头的字符串。
"(T|t)he" => The car is parked in the garage.
"^(T|t)he" => The car is parked in the garage.
2.8.2 $ 号
同理于 ^ 号,$ 号用来匹配字符是否是最后一个。
例如,(at\.)$ 匹配以 at. 结尾的字符串。
"(at\.)" => The fat cat. sat. on the mat.
"(at\.)$" => The fat cat. sat. on the mat.
3. 简写字符集
正则表达式提供一些常用的字符集简写。如下:
| 简写 | 描述 |
|---|---|
| . | 除换行符外的所有字符 |
| \w | 匹配所有字母数字,等同于 [a-zA-Z0-9_] |
| \W | 匹配所有非字母数字,即符号,等同于: [^\w] |
| \d | 匹配数字: [0-9] |
| \D | 匹配非数字: [^\d] |
| \s | 匹配所有空格字符,等同于: [\t\n\f\r\p{Z}] |
| \S | 匹配所有非空格字符: [^\s] |
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
| \p | 匹配 CR/LF(等同于 \r\n),用来匹配 DOS 行终止符 |
4. 零宽度断言(前后预查)
先行断言和后发断言都属于非捕获簇(不捕获文本 ,也不针对组合计进行计数)。
先行断言用于判断所匹配的格式是否在另一个确定的格式之前,匹配结果不包含该确定格式(仅作为约束)。
例如,我们想要获得所有跟在 $ 符号后的数字,我们可以使用正后发断言 (?<=\$)[0-9\.]*。
这个表达式匹配 $ 开头,之后跟着 0,1,2,3,4,5,6,7,8,9,. 这些字符可以出现大于等于 0 次。
零宽度断言如下:
| 符号 | 描述 |
|---|---|
| ?= | 正先行断言-存在 |
| ?! | 负先行断言-排除 |
| ?<= | 正后发断言-存在 |
| ?<! | 负后发断言-排除 |
4.1 ?=... 正先行断言
?=... 正先行断言,表示第一部分表达式之后必须跟着 ?=...定义的表达式。
返回结果只包含满足匹配条件的第一部分表达式。
定义一个正先行断言要使用 ()。在括号内部使用一个问号和等号: (?=...)。
正先行断言的内容写在括号中的等号后面。
例如,表达式 (T|t)he(?=\sfat) 匹配 The 和 the,在括号中我们又定义了正先行断言 (?=\sfat) ,即 The 和 the 后面紧跟着 (空格)fat。
"(T|t)he(?=\sfat)" => The fat cat sat on the mat.
4.2 ?!... 负先行断言
负先行断言 ?! 用于筛选所有匹配结果,筛选条件为 其后不跟随着断言中定义的格式。正先行断言 定义和 负先行断言 一样,区别就是 = 替换成 ! 也就是 (?!...)。
表达式 (T|t)he(?!\sfat) 匹配 The 和 the,且其后不跟着 (空格)fat。
"(T|t)he(?!\sfat)" => The fat cat sat on the mat.
4.3 ?<= ... 正后发断言
正后发断言 记作(?<=...) 用于筛选所有匹配结果,筛选条件为 其前跟随着断言中定义的格式。
例如,表达式 (?<=(T|t)he\s)(fat|mat) 匹配 fat 和 mat,且其前跟着 The 或 the。
"(?<=(T|t)he\s)(fat|mat)" => The fat cat sat on the mat.
4.4 ?<!... 负后发断言
负后发断言 记作 (?<!...) 用于筛选所有匹配结果,筛选条件为 其前不跟随着断言中定义的格式。
例如,表达式 (?<!(T|t)he\s)(cat) 匹配 cat,且其前不跟着 The 或 the。
"(?<!(T|t)he\s)(cat)" => The cat sat on cat.
5. 标志
标志也叫模式修正符,因为它可以用来修改表达式的搜索结果。
这些标志可以任意的组合使用,它也是整个正则表达式的一部分。
| 标志 | 描述 |
|---|---|
| i | 忽略大小写。 |
| g | 全局搜索。 |
| m | 多行修饰符:锚点元字符 ^ $ 工作范围在每行的起始。 |
5.1 忽略大小写(Case Insensitive)
修饰语 i 用于忽略大小写。
例如,表达式 /The/gi 表示在全局搜索 The,在后面的 i 将其条件修改为忽略大小写,则变成搜索 the 和 The,g 表示全局搜索。
"The" => The fat cat sat on the mat.
"/The/gi" => The fat cat sat on the mat.
5.2 全局搜索(Global search)
修饰符 g 常用于执行一个全局搜索匹配,即(不仅仅返回第一个匹配的,而是返回全部)。
例如,表达式 /.(at)/g 表示搜索 任意字符(除了换行)+ at,并返回全部结果。
"/.(at)/" => The fat cat sat on the mat.
"/.(at)/g" => The fat cat sat on the mat.
5.3 多行修饰符(Multiline)
多行修饰符 m 常用于执行一个多行匹配。
像之前介绍的 (^,$) 用于检查格式是否是在待检测字符串的开头或结尾。但我们如果想要它在每行的开头和结尾生效,我们需要用到多行修饰符 m。
例如,表达式 /at(.)?$/gm 表示小写字符 a 后跟小写字符 t ,末尾可选除换行符外任意字符。根据 m 修饰符,现在表达式匹配每行的结尾。
"/.at(.)?$/" => The fat
cat sat
on the mat.
"/.at(.)?$/gm" => The fat cat sat on the mat.
6. 贪婪匹配与惰性匹配(Greedy vs lazy matching)
正则表达式默认采用贪婪匹配模式,在该模式下意味着会匹配尽可能长的子串。我们可以使用 ? 将贪婪匹配模式转化为惰性匹配模式。
"/(.*at)/" => The fat cat sat on the mat.
"/(.*?at)/" => The fat cat sat on the mat.
贡献
- 报告问题
- 开放合并请求
- 传播此文档
- 直接和我联系 ziishaned@gmail.com 或

许可证
MIT © Zeeshan Ahmad
词法作用域与动态作用域
词法作用域
词法作用域就是定义在词法阶段的作用域。换句话说,词法作用域是由你在写代码时将变量和块作用域写在哪里来决定的,因此当词法分析器处理代码时会保持作用域不变(大部分情况下是这样的)。
1 | function foo() { |
动态作用域
动态作用域让作用域作为一个在运行时就被动态确定的形式,而不是在写代码时进行静态确定的形式
需要明确的是,事实上 JavaScript 并不具有动态作用域。它只有词法作用域,简单明了。 但是 this 机制某种程度上很像动态作用域。
主要区别:词法作用域是在写代码或者说定义时确定的,而动态作用域是在运行时确定的。(this 也是!)词法作用域关注函数在何处声明,而动态作用域关注函数从何处调用。
CSS变量
变量的声明
声明变量的时候,变量名前面要加两根连词线(–)。
1 | body { |
上面代码中,body选择器里面声明了两个变量:--foo和--bar。
它们与color、font-size等正式属性没有什么不同,只是没有默认含义。所以 CSS 变量(CSS variable)又叫做”CSS 自定义属性”(CSS custom properties)。因为变量与自定义的 CSS 属性其实是一回事。
你可能会问,为什么选择两根连词线(–)表示变量?因为$foo被 Sass 用掉了,@foo被 Less 用掉了。为了不产生冲突,官方的 CSS 变量就改用两根连词线了。
各种值都可以放入 CSS 变量。
1 | :root{ |
变量名大小写敏感,--header-color和--Header-Color是两个不同变量。
var() 函数
var()函数用于读取变量。
1 | a { |
var()函数还可以使用第二个参数,表示变量的默认值。如果该变量不存在,就会使用这个默认值。
1 | color: var(--foo, #7F583F); |
第二个参数不处理内部的逗号或空格,都视作参数的一部分。
1 | var(--font-stack, "Roboto", "Helvetica"); |
var()函数还可以用在变量的声明。
1 | :root { |
注意,变量值只能用作属性值,不能用作属性名。
1 | .foo { |
上面代码中,变量--side用作属性名,这是无效的。
变量值的类型
如果变量值是一个字符串,可以与其他字符串拼接。
1 | --bar: 'hello'; |
利用这一点,可以 debug(例子)。
1 | body:after { |
如果变量值是数值,不能与数值单位直接连用。
1 | .foo { |
上面代码中,数值与单位直接写在一起,这是无效的。必须使用calc()函数,将它们连接。
1 | .foo { |
如果变量值带有单位,就不能写成字符串。
1 | /* 无效 */ |
作用域
同一个 CSS 变量,可以在多个选择器内声明。读取的时候,优先级最高的声明生效。这与 CSS 的”层叠”(cascade)规则是一致的。
下面是一个例子。
1 | <style> |
上面代码中,三个选择器都声明了–color变量。不同元素读取这个变量的时候,会采用优先级最高的规则,因此三段文字的颜色是不一样的。
这就是说,变量的作用域就是它所在的选择器的有效范围。
1 | body { |
上面代码中,变量--foo的作用域是body选择器的生效范围,--bar的作用域是.content选择器的生效范围。
由于这个原因,全局的变量通常放在根元素:root里面,确保任何选择器都可以读取它们。
1 | document.querySelector(':root')==document.querySelector('html') |
响应式布局
CSS 是动态的,页面的任何变化,都会导致采用的规则变化。
利用这个特点,可以在响应式布局的media命令里面声明变量,使得不同的屏幕宽度有不同的变量值。
1 | body { |
兼容性处理
对于不支持 CSS 变量的浏览器,可以采用下面的写法。
1 | a { |
也可以使用@support命令进行检测。
1 | @supports ( (--a: 0)) { |
七、JavaScript 操作
JavaScript 也可以检测浏览器是否支持 CSS 变量。
1 | const isSupported = |
JavaScript 操作 CSS 变量的写法如下。
1 | // 设置变量 |
这意味着,JavaScript 可以将任意值存入样式表。下面是一个监听事件的例子,事件信息被存入 CSS 变量。
1 | const docStyle = document.documentElement.style; |
那些对 CSS 无用的信息,也可以放入 CSS 变量。
1 | --foo: if(x > 5) this.width = 10; |
上面代码中,–foo的值在 CSS 里面是无效语句,但是可以被 JavaScript 读取。这意味着,可以把样式设置写在 CSS 变量中,让 JavaScript 读取。
所以,CSS 变量提供了 JavaScript 与 CSS 通信的一种途径。
闭包
补充: 极客时间
看着简单,实际隐藏了很多东西
1 | function count(){ |
直接写成自执行函数,更加简单
1 | const countUp = (() => { |
闭包和this
1 | var name = "The Window"; |
上述代码,看似利用闭包得到了想要的this指向,实际上并不是
每个函数在被调用时都会自动取得两个特殊变量:this 和 arguments。内部函数在搜索这两个变量时,只会搜索到其活动对象为止,因此永远不可能直接访问外部函数中的这两个变量
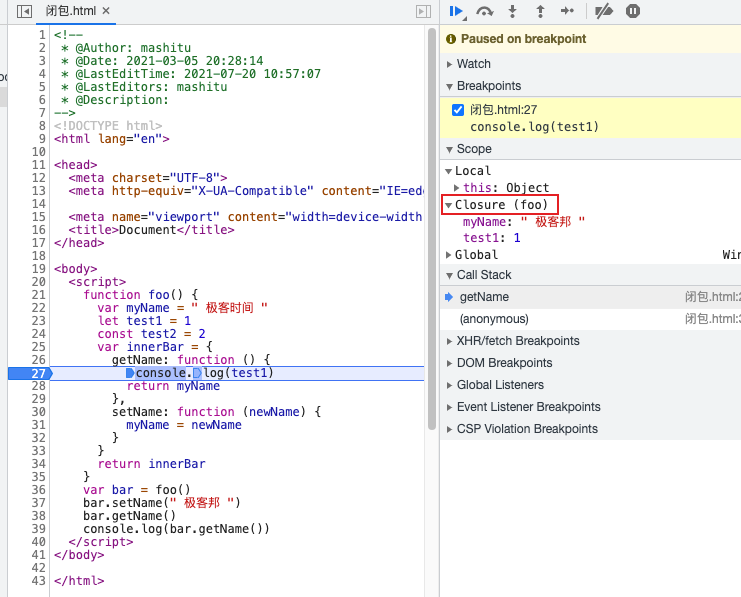
控制台看闭包
一图胜千言